Here, we’ll go over some examples of using per-protocol, censoring. First we need to load the library before getting in to some sample use cases.
Per-protocol, censoring, weights in pre-expanded data and no truncation, no excused conditions (i.e. static interventions)
options <- SEQopts(# tells SEQuential to create Kaplan-Meier curves
km.curves = TRUE,
# tells SEQuential to weight the outcome model
weighted = TRUE,
# tells SEQuential to build weights from the pre-expanded data
weight.preexpansion = TRUE)
# use some example data in the package
data <- SEQdata
model <- SEQuential(data,
id.col = "ID",
time.col = "time",
eligible.col = "eligible",
treatment.col = "tx_init",
outcome.col = "outcome",
time_varying.cols = c("N", "L", "P"),
fixed.cols = "sex",
method = "censoring",
options = options)
#>
#> Full dataset: 12,180 observations, 11 variables
#>
#> Non-required columns provided, pruning for efficiency
#>
#> Pruned
#>
#> Original dataset (eligible subjects): 9,203 observations, 9 variables
#>
#> Expanding Data...
#>
#> Pre-filter expansion: 310,080 observations
#>
#> Expanded dataset (pre-censoring): 248,485 observations, 15 variables
#>
#> Expanded dataset (post-censoring): 102,749 observations, 15 variables
#> entering outcome model (uncensored): 96,251
#> artificially censored (treatment switch): 6,498
#>
#> Expansion Successful
#>
#> Final analysis dataset: 102,749 observations, 15 variables
#>
#> Moving forward with censoring analysis
#>
#> censoring model created successfully
#>
#> Creating Survival curves
#>
#> Completed
# retrieve risk plot
km_curve(model, plot.type = "risk")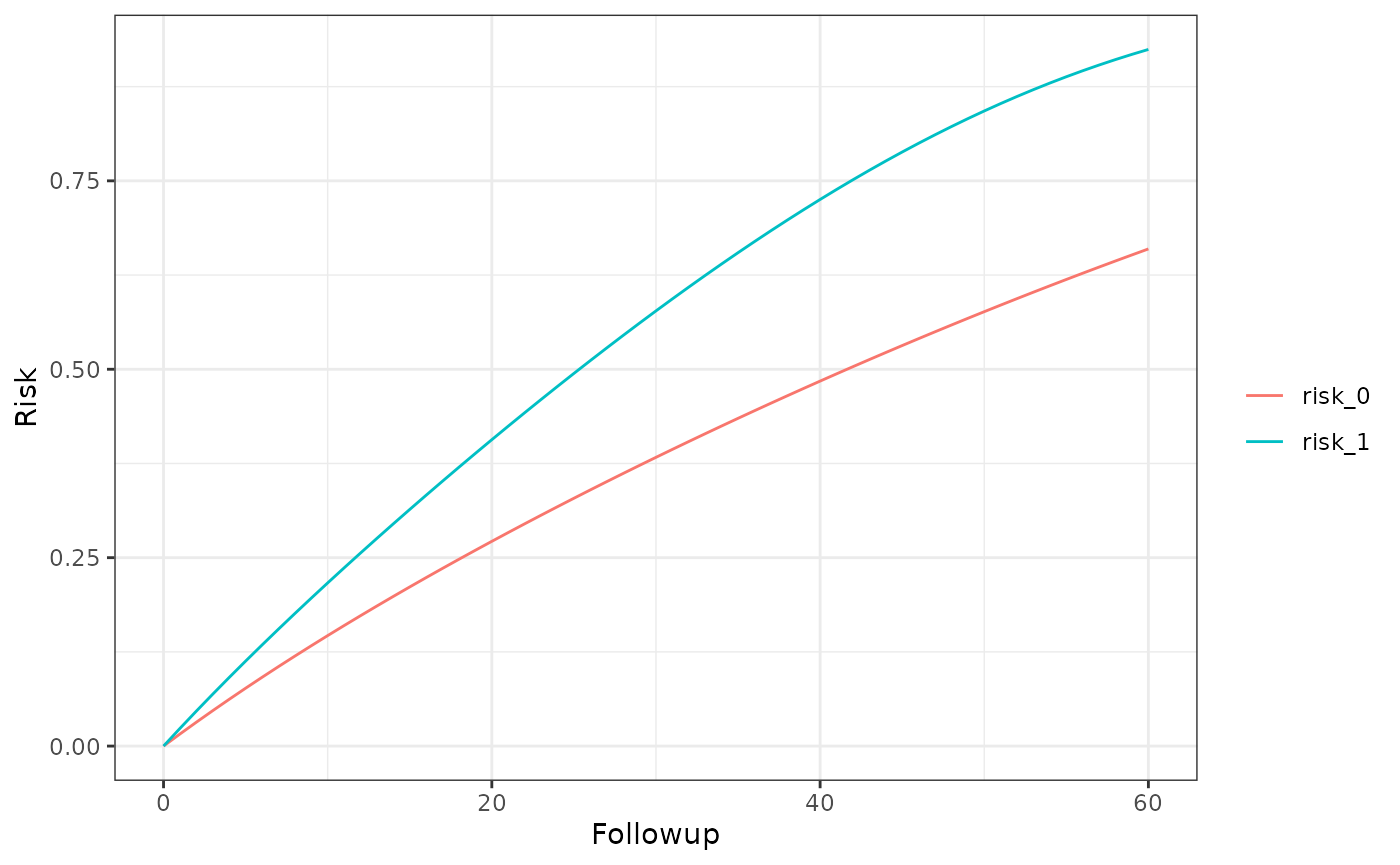
# retrieve survival and risk data
survival_data <- km_data(model)
risk_data(model)
#> Index: <Followup>
#> Method Followup A Risk
#> <char> <num> <char> <num>
#> 1: censoring 60 0 0.6596589
#> 2: censoring 60 1 0.9243520
risk_comparison(model)
#> Followup A_x A_y Risk Ratio Risk Difference
#> <num> <fctr> <fctr> <num> <num>
#> 1: 60 risk_0 risk_1 1.4012576 0.2646931
#> 2: 60 risk_1 risk_0 0.7136447 -0.2646931Per-protocol, censoring, weights in post-expanded data and no truncation, no excused conditions (i.e. static interventions)
options <- SEQopts(km.curves = TRUE,
weighted = TRUE,
# tells SEQuential to build weights from the post-expanded data
weight.preexpansion = FALSE)
data <- SEQdata
model <- SEQuential(data,
id.col = "ID",
time.col = "time",
eligible.col = "eligible",
treatment.col = "tx_init",
outcome.col = "outcome",
time_varying.cols = c("N", "L", "P"),
fixed.cols = "sex",
method = "censoring",
options = options)
#>
#> Full dataset: 12,180 observations, 11 variables
#>
#> Non-required columns provided, pruning for efficiency
#>
#> Pruned
#>
#> Original dataset (eligible subjects): 9,203 observations, 9 variables
#>
#> Expanding Data...
#>
#> Pre-filter expansion: 310,080 observations
#>
#> Expanded dataset (pre-censoring): 248,485 observations, 18 variables
#>
#> Expanded dataset (post-censoring): 102,749 observations, 18 variables
#> entering outcome model (uncensored): 96,251
#> artificially censored (treatment switch): 6,498
#>
#> Expansion Successful
#>
#> Final analysis dataset: 102,749 observations, 18 variables
#>
#> Moving forward with censoring analysis
#>
#> censoring model created successfully
#>
#> Creating Survival curves
#>
#> Completed
km_curve(model, plot.type = "risk")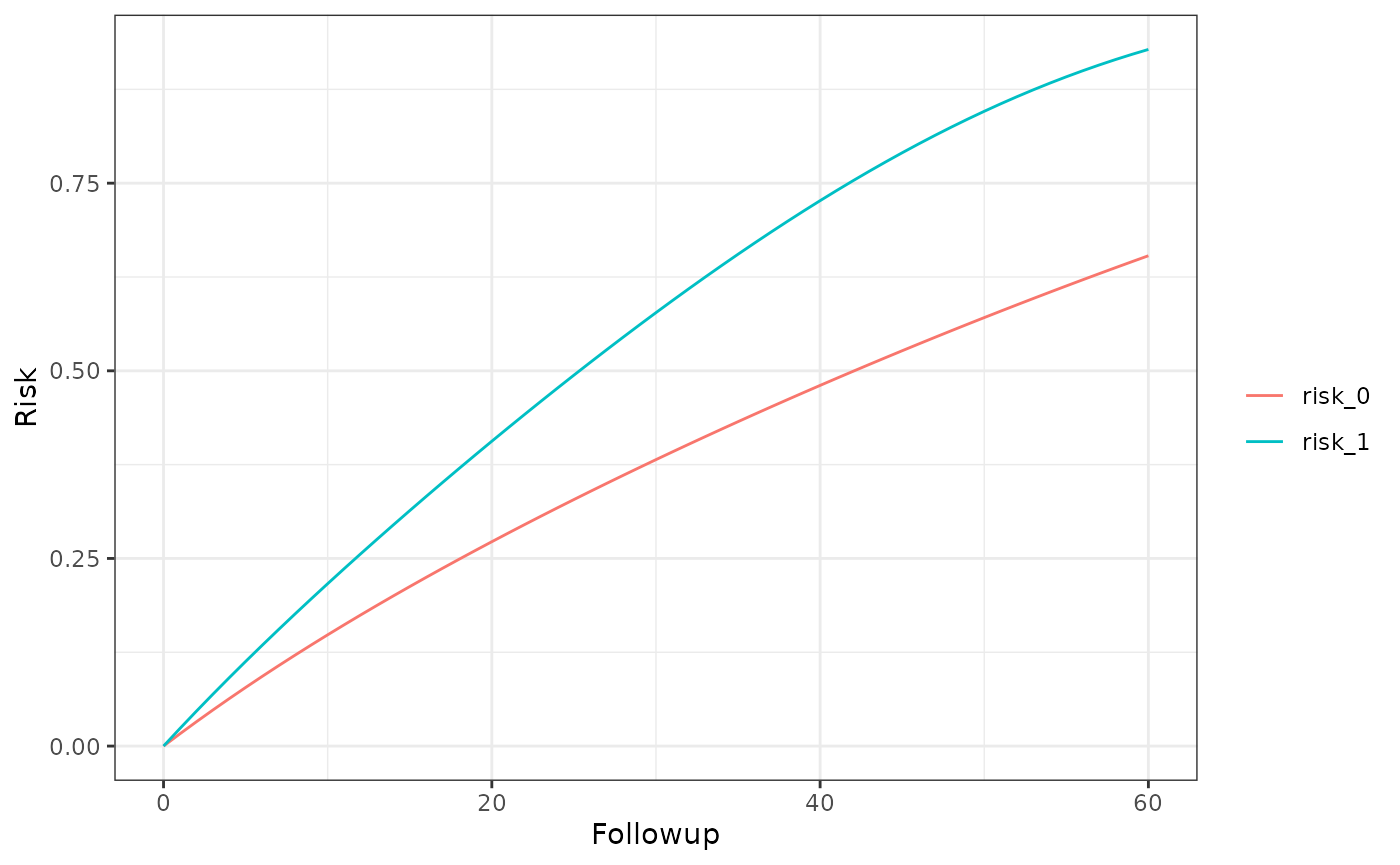
risk_data(model)
#> Index: <Followup>
#> Method Followup A Risk
#> <char> <num> <char> <num>
#> 1: censoring 60 0 0.6533049
#> 2: censoring 60 1 0.9281893
risk_comparison(model)
#> Followup A_x A_y Risk Ratio Risk Difference
#> <num> <fctr> <fctr> <num> <num>
#> 1: 60 risk_0 risk_1 1.4207598 0.2748844
#> 2: 60 risk_1 risk_0 0.7038488 -0.2748844Per-protocol, censoring, weights in pre-expanded data and no truncation, excused conditions for initiators and non-initiators (i.e. dynamic interventions)
options <- SEQopts(km.curves = TRUE,
weighted = TRUE,
weight.preexpansion = TRUE,
# tells SEQuential to run a dynamic intervention
excused = TRUE,
# tells SEQuential to use columns excusedOne and
# excusedZero as excused conditions for treatment switches
excused.cols = c("excusedZero", "excusedOne"),
# tells SEQuential to expect treatment levels 0, 1
# (mapping to the same positions as the list in excused.cols)
treat.level = c(0, 1))
data <- SEQdata
model <- SEQuential(data,
id.col = "ID",
time.col = "time",
eligible.col = "eligible",
treatment.col = "tx_init",
outcome.col = "outcome",
time_varying.cols = c("N", "L", "P"),
fixed.cols = "sex",
method = "censoring",
options = options)
#>
#> Full dataset: 12,180 observations, 11 variables
#>
#> Original dataset (eligible subjects): 9,203 observations, 11 variables
#>
#> Expanding Data...
#>
#> Pre-filter expansion: 310,080 observations
#>
#> Expanded dataset (pre-censoring): 248,485 observations, 18 variables
#>
#> Expanded dataset (post-censoring): 185,423 observations, 18 variables
#> entering outcome model (uncensored): 183,315
#> artificially censored (treatment switch): 2,108
#>
#> Expansion Successful
#>
#> Final analysis dataset: 185,423 observations, 18 variables
#>
#> Moving forward with censoring analysis
#>
#> censoring model created successfully
#>
#> Creating Survival curves
#>
#> Completed
km_curve(model, plot.type = "risk")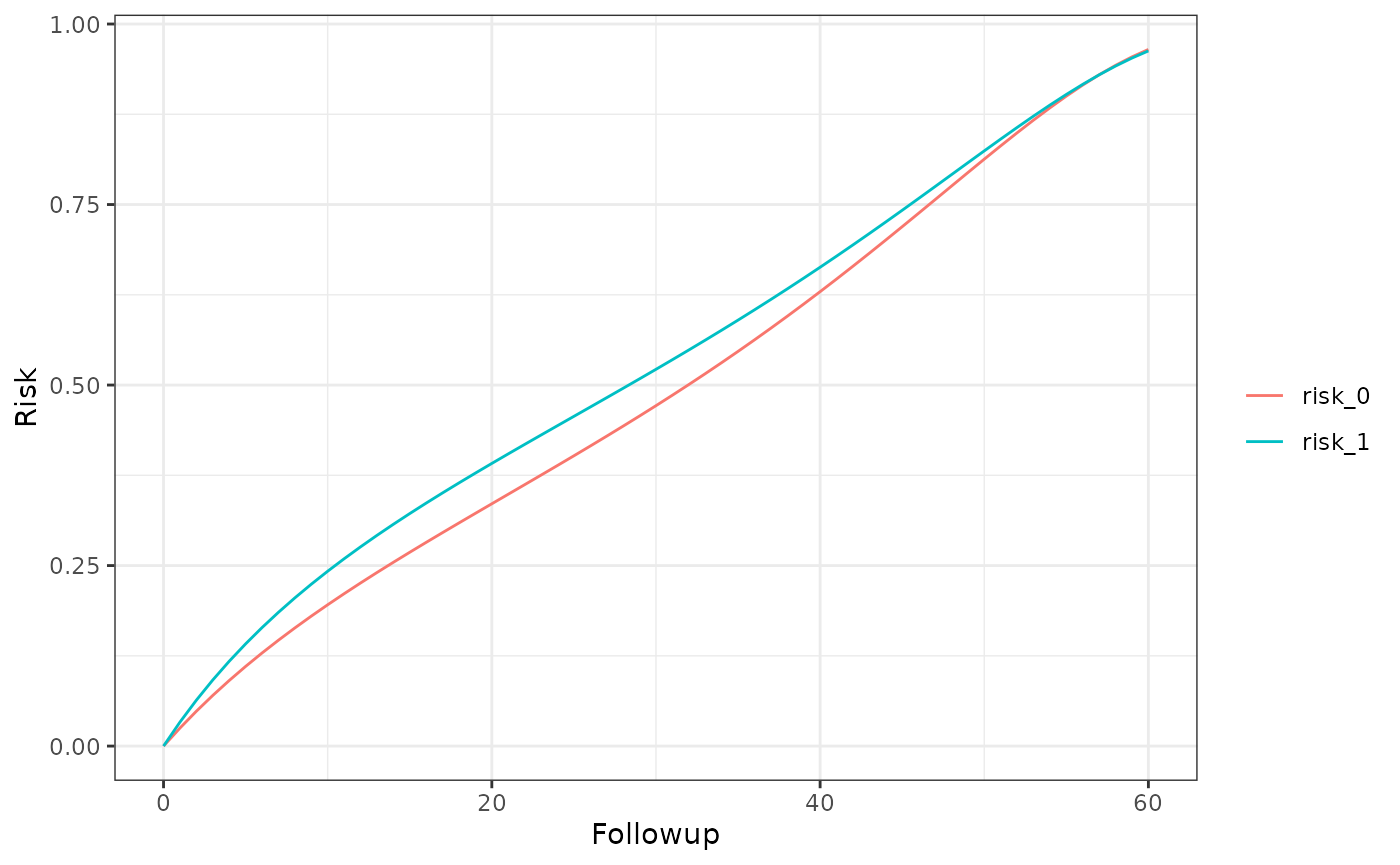
risk_data(model)
#> Index: <Followup>
#> Method Followup A Risk
#> <char> <num> <char> <num>
#> 1: censoring 60 0 0.9647942
#> 2: censoring 60 1 0.9627635
risk_comparison(model)
#> Followup A_x A_y Risk Ratio Risk Difference
#> <num> <fctr> <fctr> <num> <num>
#> 1: 60 risk_0 risk_1 0.9978953 -0.002030621
#> 2: 60 risk_1 risk_0 1.0021092 0.002030621Per-protocol, censoring, weights in post-expanded data and no truncation, excused conditions for initiators and non-initiators (i.e. dynamic interventions)
options <- SEQopts(km.curves = TRUE,
weighted = TRUE,
weight.preexpansion = FALSE,
excused = TRUE,
excused.cols = c("excusedZero", "excusedOne"),
treat.level = c(0, 1),
weight.p99 = TRUE)
data <- SEQdata
model <- SEQuential(data,
id.col = "ID",
time.col = "time",
eligible.col = "eligible",
treatment.col = "tx_init",
outcome.col = "outcome",
time_varying.cols = c("N", "L", "P"),
fixed.cols = "sex",
method = "censoring",
options = options)
#>
#> Full dataset: 12,180 observations, 11 variables
#>
#> Original dataset (eligible subjects): 9,203 observations, 11 variables
#>
#> Expanding Data...
#>
#> Pre-filter expansion: 310,080 observations
#>
#> Expanded dataset (pre-censoring): 248,485 observations, 21 variables
#>
#> Expanded dataset (post-censoring): 185,423 observations, 21 variables
#> entering outcome model (uncensored): 183,315
#> artificially censored (treatment switch): 2,108
#>
#> Expansion Successful
#>
#> Final analysis dataset: 185,423 observations, 21 variables
#>
#> Moving forward with censoring analysis
#>
#> censoring model created successfully
#>
#> Creating Survival curves
#>
#> Completed
km_curve(model, plot.type = "risk")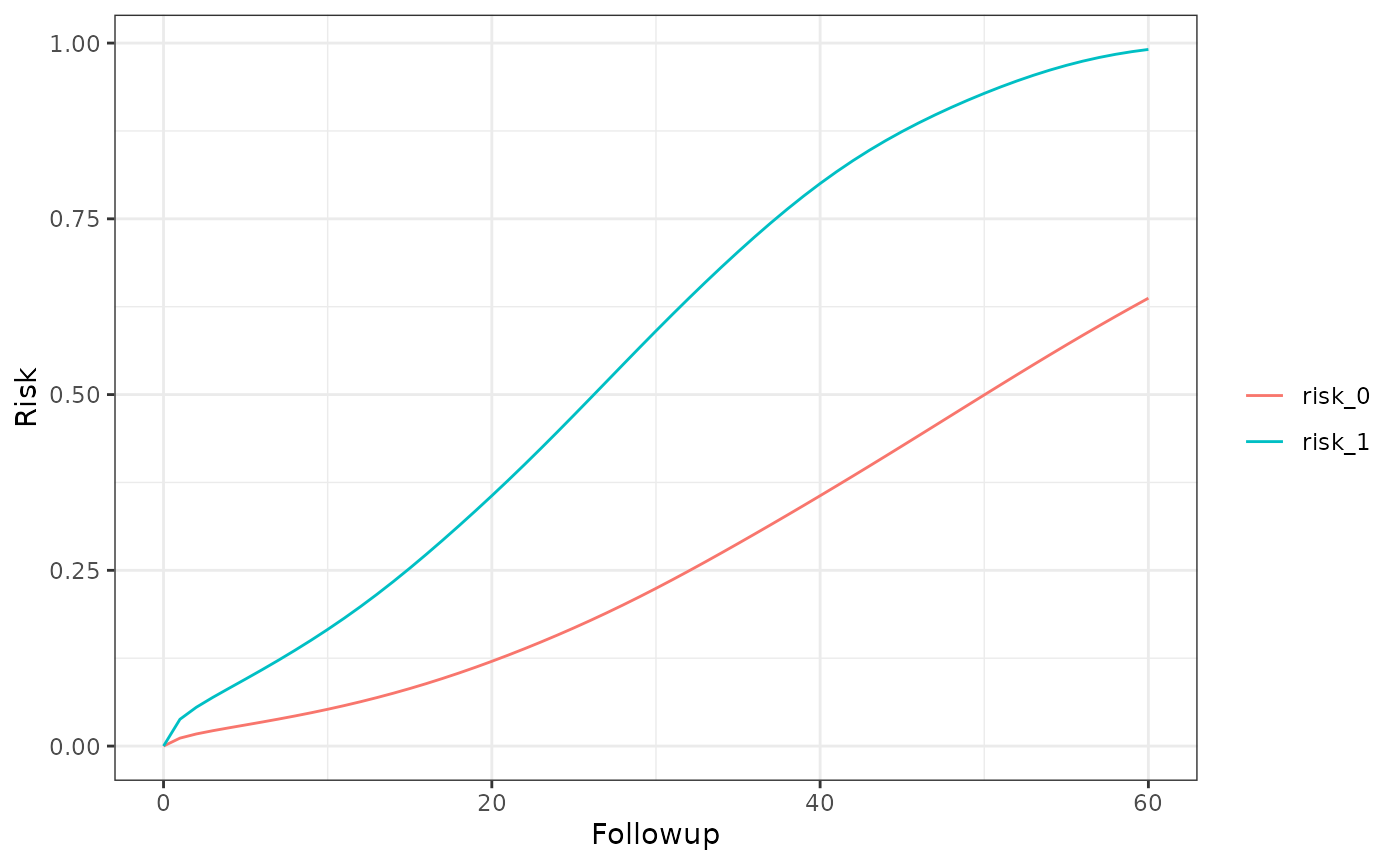
risk_data(model)
#> Index: <Followup>
#> Method Followup A Risk
#> <char> <num> <char> <num>
#> 1: censoring 60 0 0.6371076
#> 2: censoring 60 1 0.9909442
risk_comparison(model)
#> Followup A_x A_y Risk Ratio Risk Difference
#> <num> <fctr> <fctr> <num> <num>
#> 1: 60 risk_0 risk_1 1.5553797 0.3538366
#> 2: 60 risk_1 risk_0 0.6429298 -0.3538366Per-protocol, censoring, weights in post-expanded data and no truncation, excused conditions for initiators and non-initiators (i.e. dynamic interventions) and a competing event
options <- SEQopts(km.curves = TRUE,
weighted = TRUE,
weight.preexpansion = FALSE,
excused = TRUE,
excused.cols = c("excusedZero", "excusedOne"),
treat.level = c(0, 1),
# add a competing event
compevent = "LTFU")
data <- SEQdata.LTFU
model <- SEQuential(data,
id.col = "ID",
time.col = "time",
eligible.col = "eligible",
treatment.col = "tx_init",
outcome.col = "outcome",
time_varying.cols = c("N", "L", "P"),
fixed.cols = "sex",
method = "censoring",
options = options)
#>
#> Full dataset: 54,687 observations, 13 variables
#>
#> Non-required columns provided, pruning for efficiency
#>
#> Pruned
#>
#> Original dataset (eligible subjects): 29,624 observations, 12 variables
#>
#> Expanding Data...
#>
#> Pre-filter expansion: 1,609,859 observations
#>
#> Expanded dataset (pre-censoring): 1,119,229 observations, 22 variables
#>
#> Expanded dataset (post-censoring): 810,880 observations, 22 variables
#> entering outcome model (uncensored): 803,021
#> artificially censored (treatment switch): 7,859
#>
#> Expansion Successful
#>
#> Final analysis dataset: 810,880 observations, 22 variables
#>
#> Moving forward with censoring analysis
#>
#> censoring model created successfully
#>
#> Creating Survival curves
#>
#> Completed
km_curve(model, plot.type = "risk")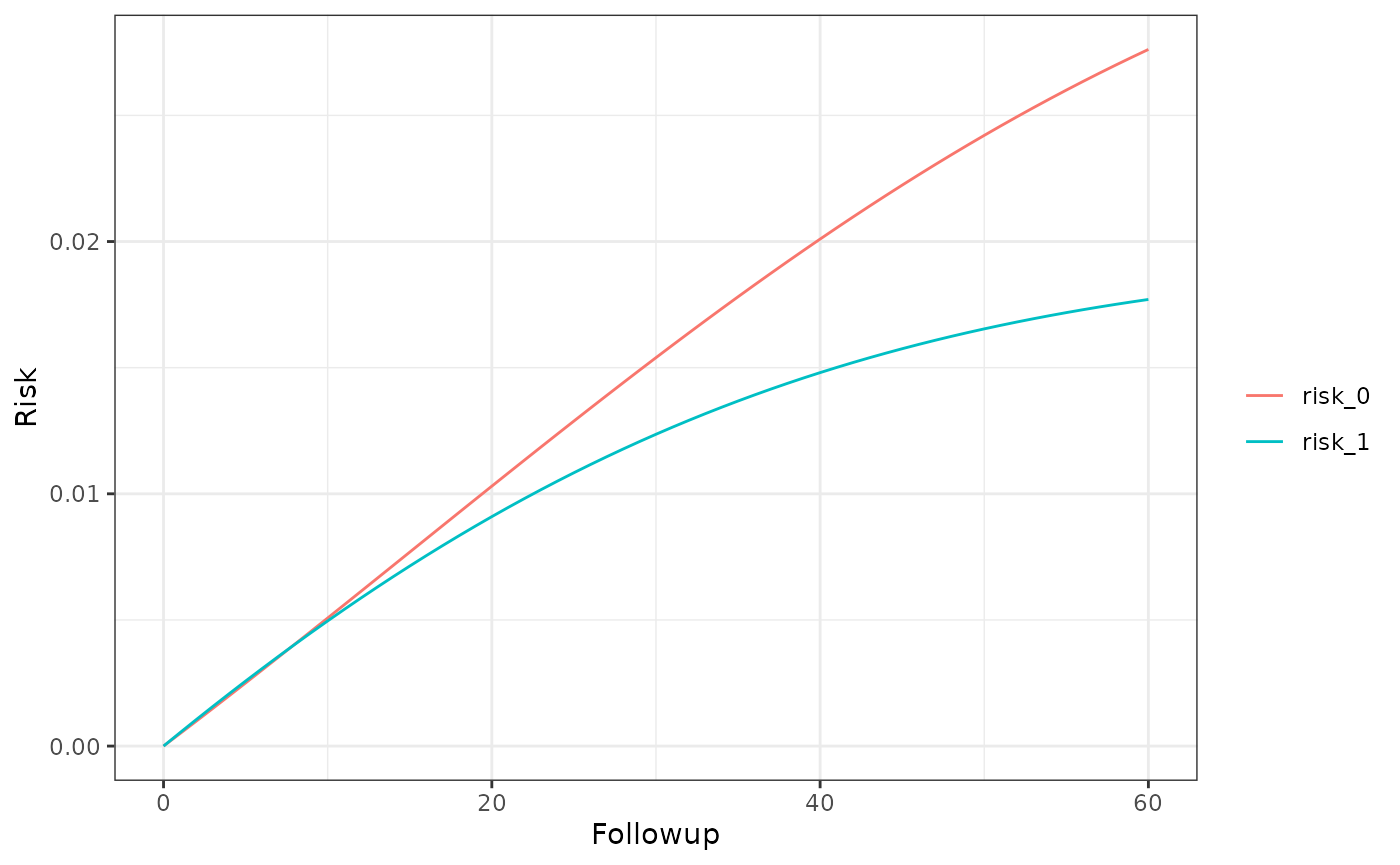
risk_data(model)
#> Index: <Followup>
#> Method Followup A Risk
#> <char> <num> <char> <num>
#> 1: censoring 60 0 0.02542994
#> 2: censoring 60 1 0.01646542
risk_comparison(model)
#> Followup A_x A_y Risk Ratio Risk Difference
#> <num> <fctr> <fctr> <num> <num>
#> 1: 60 inc_0 inc_1 0.6474815 -0.008964524
#> 2: 60 inc_1 inc_0 1.5444456 0.008964524Per-protocol, censoring, weights in post-expanded data and no truncation, excused conditions for initiators and non-initiators (i.e. dynamic interventions) and hazard ratio
options <- SEQopts(# tell SEQuential to run hazard ratios
hazard = TRUE,
weighted = TRUE,
weight.preexpansion = FALSE,
excused = TRUE,
excused.cols = c("excusedZero", "excusedOne"),
weight.p99 = TRUE)
data <- SEQdata
model <- SEQuential(data,
id.col = "ID",
time.col = "time",
eligible.col = "eligible",
treatment.col = "tx_init",
outcome.col = "outcome",
time_varying.cols = c("N", "L", "P"),
fixed.cols = "sex",
method = "censoring",
options = options)
#>
#> Full dataset: 12,180 observations, 11 variables
#>
#> Original dataset (eligible subjects): 9,203 observations, 11 variables
#>
#> Expanding Data...
#>
#> Pre-filter expansion: 310,080 observations
#>
#> Expanded dataset (pre-censoring): 248,485 observations, 21 variables
#>
#> Expanded dataset (post-censoring): 185,423 observations, 21 variables
#> entering outcome model (uncensored): 183,315
#> artificially censored (treatment switch): 2,108
#>
#> Expansion Successful
#>
#> Final analysis dataset: 185,423 observations, 21 variables
#>
#> Moving forward with censoring analysis
#>
#> Completed
hazard_ratio(model)
#> Hazard ratio LCI UCI
#> 3.004905 NA NA