Here, we’ll go over some examples of using dose-response. First we need to load the library before getting in to some sample use cases.
Currently, dose-response analysis through SEQuential only supports binary treatment values. Therefore; running multinomial models will lead to errors.
Dose-response With 5 bootstrap samples
options <- SEQopts(# tells SEQuential to create Kaplan-Meier curves
km.curves = TRUE,
# tells SEQuential to bootstrap
bootstrap = TRUE,
# tells SEQuential to run bootstraps 5 times
bootstrap.nboot = 5)
# use example data
data <- SEQdata
model <- SEQuential(data, id.col = "ID",
time.col = "time",
eligible.col = "eligible",
treatment.col = "tx_init",
outcome.col = "outcome",
time_varying.cols = c("N", "L", "P"),
fixed.cols = "sex",
method = "dose-response",
options = options)
#>
#> Full dataset: 12,180 observations, 11 variables
#>
#> Non-required columns provided, pruning for efficiency
#>
#> Pruned
#>
#> Original dataset (eligible subjects): 9,203 observations, 9 variables
#>
#> Expanding Data...
#>
#> Pre-filter expansion: 310,080 observations
#>
#> Expanded dataset: 248,485 observations, 15 variables
#>
#> Expansion Successful
#>
#> Final analysis dataset: 248,485 observations, 15 variables
#>
#> Moving forward with dose-response analysis
#>
#> Bootstrapping with 80% of 300 subjects (240 subjects, ~198,788 observations per resample) 5 times
#>
#> dose-response model created successfully
#>
#> Creating Survival curves
#>
#> Completed
km_curve(model, plot.type = "risk") # retrieve risk plot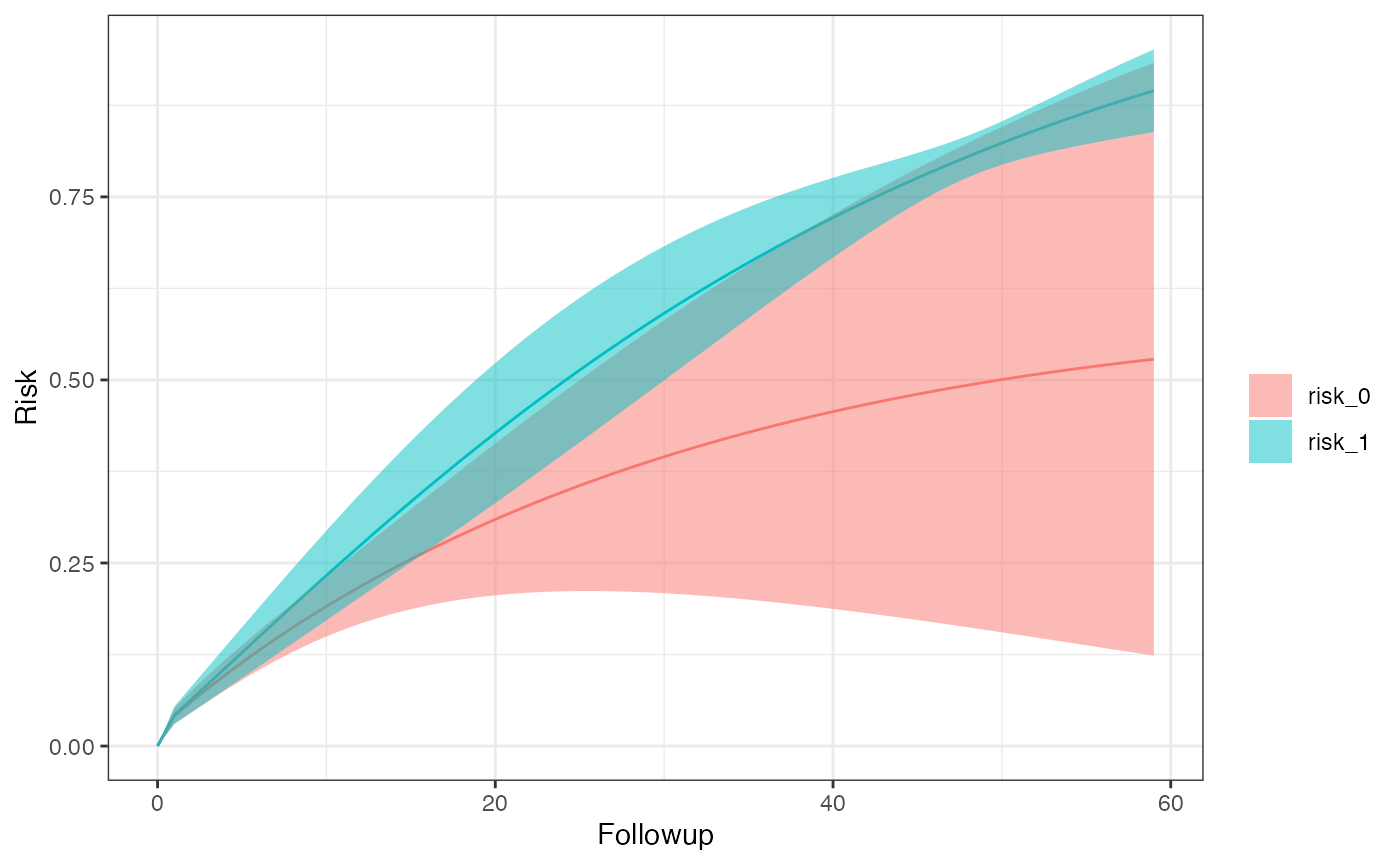
risk_data(model)
#> Index: <Followup>
#> Method Followup A Risk 95% LCI 95% UCI SE
#> <char> <num> <char> <num> <num> <num> <num>
#> 1: dose-response 60 0 0.5282782 0.2410166 0.8155398 0.14656473
#> 2: dose-response 60 1 0.8949096 0.8063496 0.9834697 0.04518453
risk_comparison(model)
#> Followup A_x A_y Risk Ratio RR 95% LCI RR 95% UCI log(RR) SE
#> <num> <fctr> <fctr> <num> <num> <num> <num>
#> 1: 60 risk_0 risk_1 1.6940120 0.8652189 3.316706 0.3427983
#> 2: 60 risk_1 risk_0 0.5903146 0.3015040 1.155777 0.3427983
#> Risk Difference RD 95% LCI RD 95% UCI RD SE
#> <num> <num> <num> <num>
#> 1: 0.3666314 0.06783115 0.66543165 0.1524519
#> 2: -0.3666314 -0.66543165 -0.06783115 0.1524519Dose-response with 5 bootstrap samples and losses-to-followup
options <- SEQopts(km.curves = TRUE,
bootstrap = TRUE,
bootstrap.nboot = 5,
# tells SEQuential to expect LTFU as the censoring column
cense = "LTFU",
# tells SEQuential to treat this column as the
# censoring eligibility column
cense.eligible = "eligible_cense")
# use example data for LTFU
data <- SEQdata.LTFU
model <- SEQuential(data, id.col = "ID",
time.col = "time",
eligible.col = "eligible",
treatment.col = "tx_init",
outcome.col = "outcome",
time_varying.cols = c("N", "L", "P"),
fixed.cols = "sex",
method = "dose-response",
options = options)
#>
#> Full dataset: 54,687 observations, 13 variables
#>
#> Non-required columns provided, pruning for efficiency
#>
#> Pruned
#>
#> Original dataset (eligible subjects): 29,624 observations, 11 variables
#>
#> Expanding Data...
#>
#> Pre-filter expansion: 1,609,859 observations
#>
#> Expanded dataset: 1,119,229 observations, 17 variables
#>
#> Expansion Successful
#>
#> Final analysis dataset: 1,119,229 observations, 17 variables
#>
#> Moving forward with dose-response analysis
#>
#> Bootstrapping with 80% of 1,000 subjects (800 subjects, ~895,383 observations per resample) 5 times
#>
#> dose-response model created successfully
#>
#> Creating Survival curves
#>
#> Completed
km_curve(model, plot.type = "risk")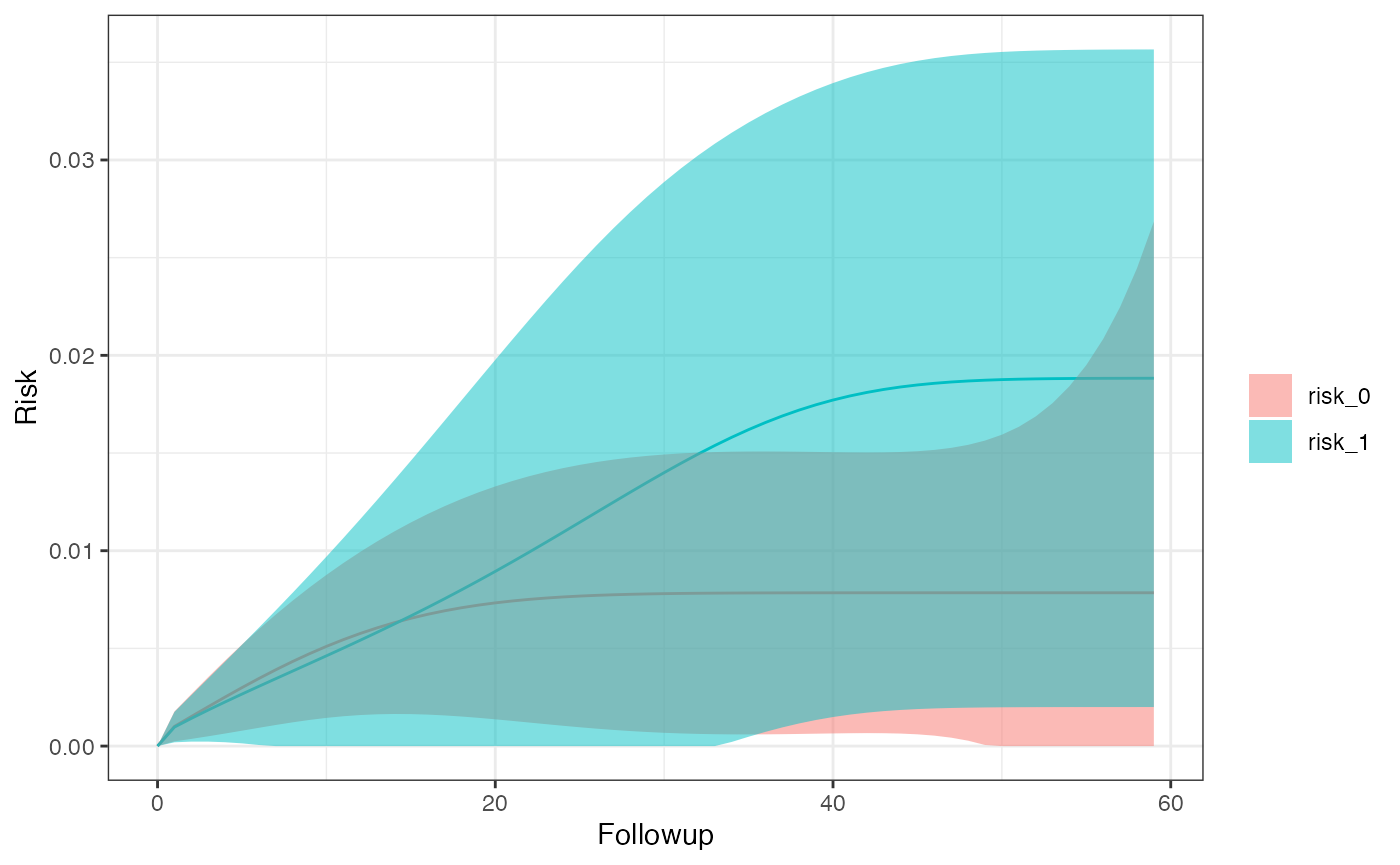
risk_data(model)
#> Index: <Followup>
#> Method Followup A Risk 95% LCI 95% UCI SE
#> <char> <num> <char> <num> <num> <num> <num>
#> 1: dose-response 60 0 0.007847443 0 0.02529929 0.00890417
#> 2: dose-response 60 1 0.018827788 0 0.04862160 0.01520121
risk_comparison(model)
#> Followup A_x A_y Risk Ratio RR 95% LCI RR 95% UCI log(RR) SE
#> <num> <fctr> <fctr> <num> <num> <num> <num>
#> 1: 60 risk_0 risk_1 2.3992259 0.042419739 135.69826 2.058858
#> 2: 60 risk_1 risk_0 0.4168011 0.007369291 23.57393 2.058858
#> Risk Difference RD 95% LCI RD 95% UCI RD SE
#> <num> <num> <num> <num>
#> 1: 0.01098034 -0.01230360 0.03426429 0.01187978
#> 2: -0.01098034 -0.03426429 0.01230360 0.01187978Dose-response with 5 bootstrap samples and competing events
options <- SEQopts(km.curves = TRUE,
bootstrap = TRUE,
bootstrap.nboot = 5,
# Using LTFU as our competing event
compevent = "LTFU")
data <- SEQdata.LTFU
model <- SEQuential(data, id.col = "ID",
time.col = "time",
eligible.col = "eligible",
treatment.col = "tx_init",
outcome.col = "outcome",
time_varying.cols = c("N", "L", "P"),
fixed.cols = "sex",
method = "dose-response",
options = options)
#>
#> Full dataset: 54,687 observations, 13 variables
#>
#> Non-required columns provided, pruning for efficiency
#>
#> Pruned
#>
#> Original dataset (eligible subjects): 29,624 observations, 10 variables
#>
#> Expanding Data...
#>
#> Pre-filter expansion: 1,609,859 observations
#>
#> Expanded dataset: 1,119,229 observations, 16 variables
#>
#> Expansion Successful
#>
#> Final analysis dataset: 1,119,229 observations, 16 variables
#>
#> Moving forward with dose-response analysis
#>
#> Bootstrapping with 80% of 1,000 subjects (800 subjects, ~895,383 observations per resample) 5 times
#>
#> dose-response model created successfully
#>
#> Creating Survival curves
#>
#> Completed
km_curve(model, plot.type = "risk")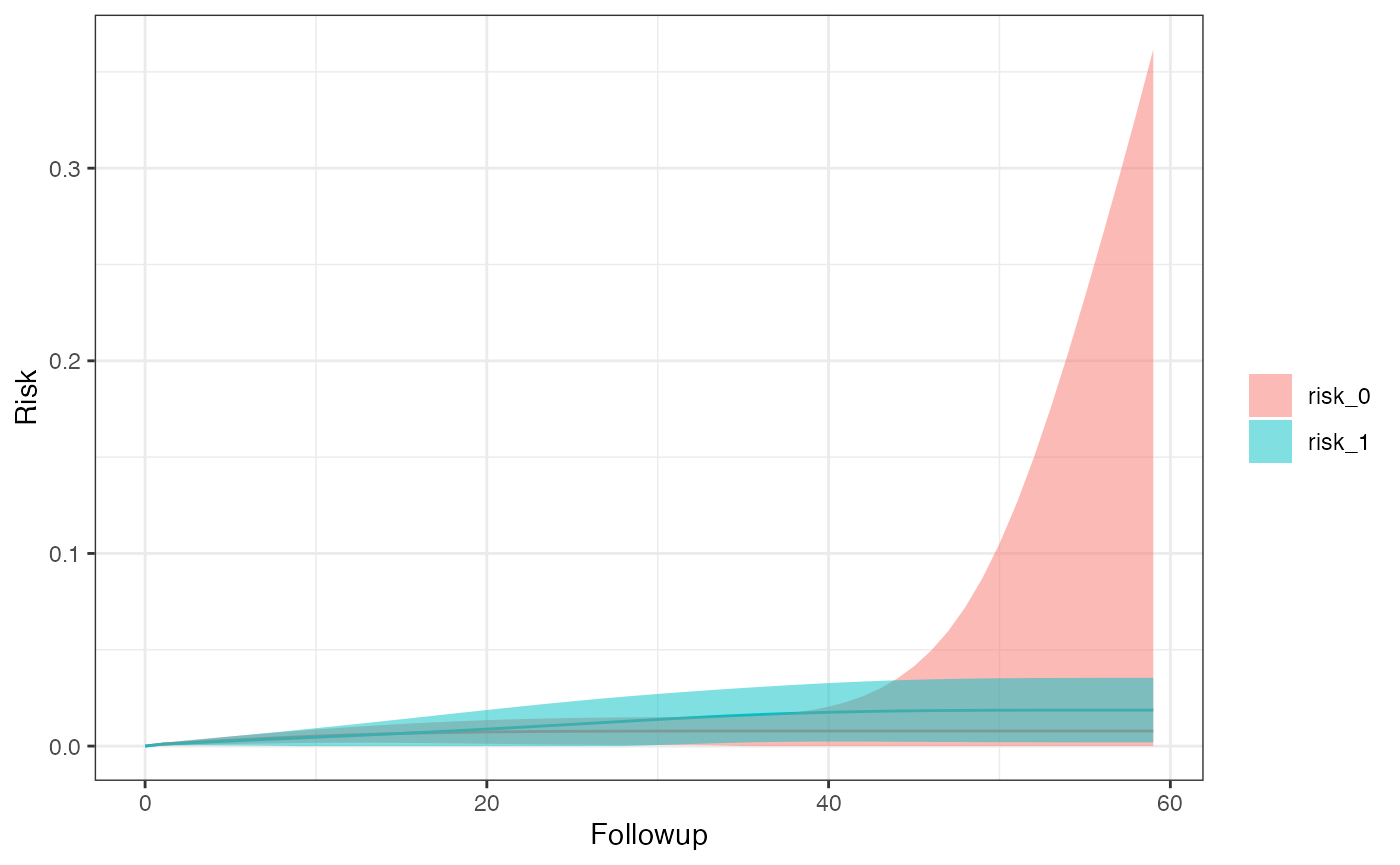
risk_data(model)
#> Index: <Followup>
#> Method Followup A Risk 95% LCI 95% UCI SE
#> <char> <num> <char> <num> <num> <num> <num>
#> 1: dose-response 60 0 0.007586789 0 0.03490503 0.013938132
#> 2: dose-response 60 1 0.003641046 0 0.01433665 0.005457039
risk_comparison(model)
#> Followup A_x A_y Risk Ratio RR 95% LCI RR 95% UCI log(RR) SE
#> <num> <fctr> <fctr> <num> <num> <num> <num>
#> 1: 60 inc_0 inc_1 0.4799192 0.05640515 4.083358 1.092396
#> 2: 60 inc_1 inc_0 2.0836841 0.24489645 17.728878 1.092396
#> Risk Difference RD 95% LCI RD 95% UCI RD SE
#> <num> <num> <num> <num>
#> 1: -0.003945743 -0.03178104 0.02388956 0.01420194
#> 2: 0.003945743 -0.02388956 0.03178104 0.01420194Dose-response hazard ratio with 5 bootstrap samples and competing events
options <- SEQopts(# km.curves must be set to FALSE to turn on hazard
# ratio creation
km.curves = FALSE,
# set hazard to TRUE for hazard ratio creation
hazard = TRUE,
bootstrap = TRUE,
bootstrap.nboot = 5,
compevent = "LTFU")
data <- SEQdata.LTFU
model <- SEQuential(data, id.col = "ID",
time.col = "time",
eligible.col = "eligible",
treatment.col = "tx_init",
outcome.col = "outcome",
time_varying.cols = c("N", "L", "P"),
fixed.cols = "sex",
method = "dose-response",
options = options)
#>
#> Full dataset: 54,687 observations, 13 variables
#>
#> Non-required columns provided, pruning for efficiency
#>
#> Pruned
#>
#> Original dataset (eligible subjects): 29,624 observations, 10 variables
#>
#> Expanding Data...
#>
#> Pre-filter expansion: 1,609,859 observations
#>
#> Expanded dataset: 1,119,229 observations, 16 variables
#>
#> Expansion Successful
#>
#> Final analysis dataset: 1,119,229 observations, 16 variables
#>
#> Moving forward with dose-response analysis
#>
#> Bootstrapping with 80% of 1,000 subjects (800 subjects, ~895,383 observations per resample) 5 times
#>
#> Completed
# retrieve hazard ratios
hazard_ratio(model)
#> Hazard ratio LCI UCI
#> 1.0475025 0.9029331 1.2152191Dose-response with 5 bootstrap samples and competing events in subgroups defined by sex
options <- SEQopts(km.curves = TRUE,
bootstrap = TRUE,
bootstrap.nboot = 5,
compevent = "LTFU",
# define the subgroup
subgroup = "sex")
data <- SEQdata.LTFU
model <- SEQuential(data, id.col = "ID",
time.col = "time",
eligible.col = "eligible",
treatment.col = "tx_init",
outcome.col = "outcome",
time_varying.cols = c("N", "L", "P"),
fixed.cols = "sex",
method = "dose-response",
options = options)
#>
#> Full dataset: 54,687 observations, 13 variables
#>
#> Non-required columns provided, pruning for efficiency
#>
#> Pruned
#>
#> Original dataset (eligible subjects): 29,624 observations, 10 variables
#>
#> Expanding Data...
#>
#> Pre-filter expansion: 1,609,859 observations
#>
#> Expanded dataset: 1,119,229 observations, 16 variables
#>
#> Expansion Successful
#>
#> Final analysis dataset: 1,119,229 observations, 16 variables
#>
#> Moving forward with dose-response analysis
#>
#> Bootstrapping with 80% of 1,000 subjects (800 subjects, ~895,383 observations per resample) 5 times
#>
#> dose-response model created successfully
#>
#> Creating Survival Curves for sex_0
#>
#> Creating Survival Curves for sex_1
#>
#> Completed
km_curve(model, plot.type = "risk")
#> $sex_0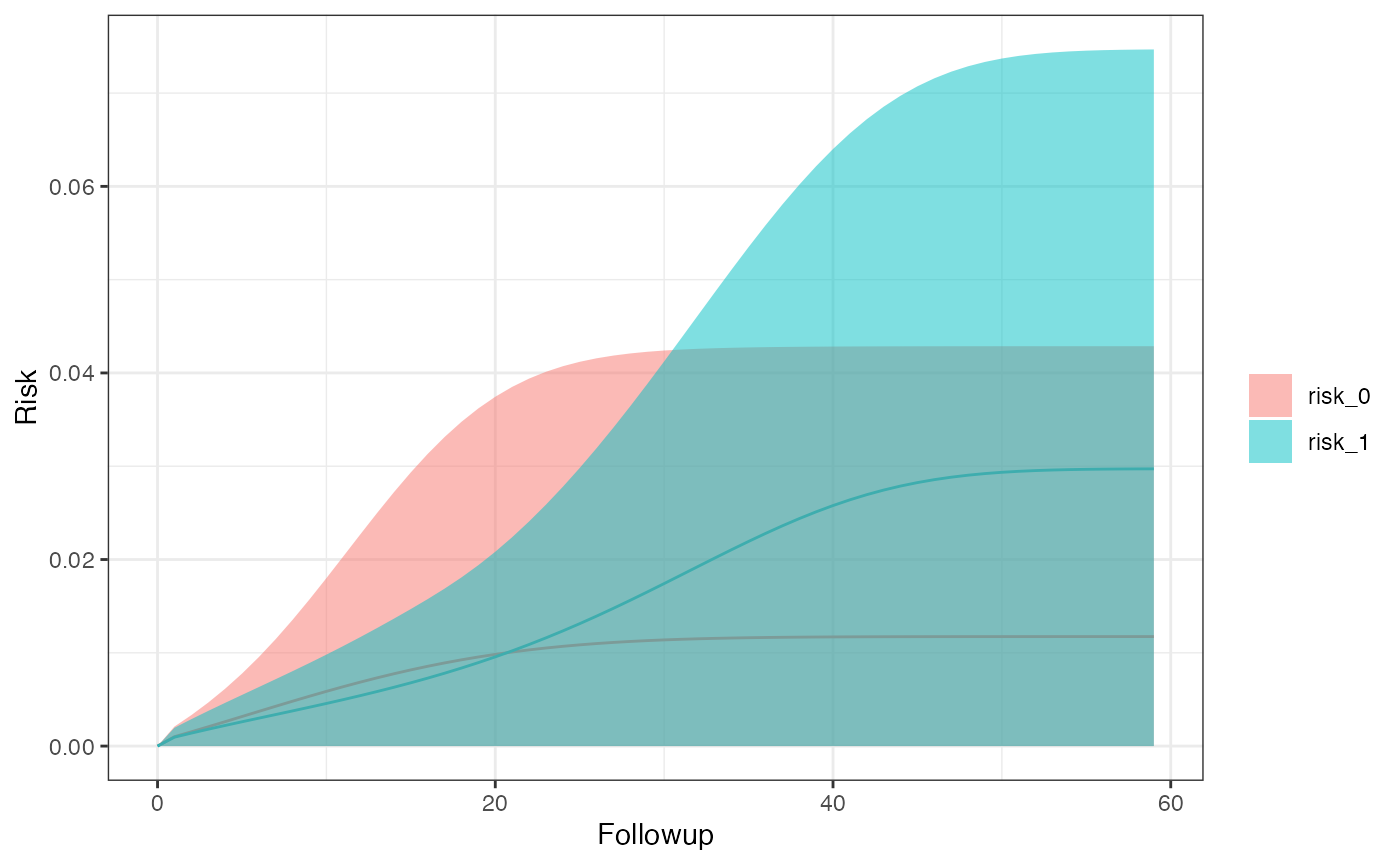
#>
#> $sex_1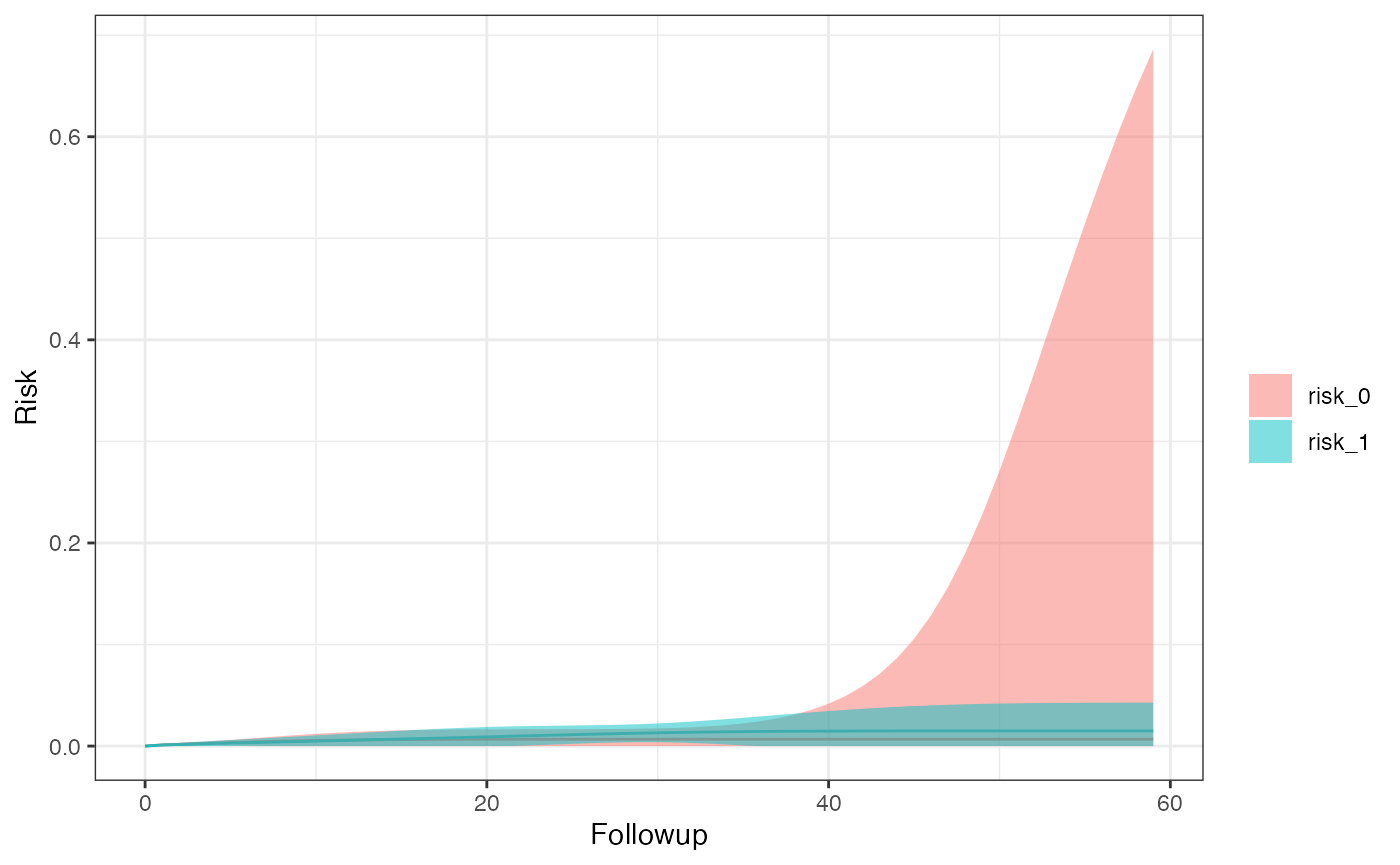
risk_data(model)
#> $sex_0
#> Index: <Followup>
#> Method Followup A Risk 95% LCI 95% UCI SE
#> <char> <num> <char> <num> <num> <num> <num>
#> 1: dose-response 60 0 0.01125753 0.000000000 0.06740746 0.028648449
#> 2: dose-response 60 1 0.01869016 0.007998263 0.02938205 0.005455149
#>
#> $sex_1
#> Index: <Followup>
#> Method Followup A Risk 95% LCI 95% UCI SE
#> <char> <num> <char> <num> <num> <num> <num>
#> 1: dose-response 60 0 0.00659838 0 0.02173867 0.007724777
#> 2: dose-response 60 1 0.01221464 0 0.02765749 0.007879153
risk_comparison(model)
#> $sex_0
#> Followup A_x A_y Risk Ratio RR 95% LCI RR 95% UCI log(RR) SE
#> <num> <fctr> <fctr> <num> <num> <num> <num>
#> 1: 60 inc_0 inc_1 1.6602358 0.0021614680 1275.2365 3.389821
#> 2: 60 inc_1 inc_0 0.6023241 0.0007841683 462.6485 3.389821
#> Risk Difference RD 95% LCI RD 95% UCI RD SE
#> <num> <num> <num> <num>
#> 1: 0.007432626 -0.05399801 0.06886327 0.03134274
#> 2: -0.007432626 -0.06886327 0.05399801 0.03134274
#>
#> $sex_1
#> Followup A_x A_y Risk Ratio RR 95% LCI RR 95% UCI log(RR) SE
#> <num> <fctr> <fctr> <num> <num> <num> <num>
#> 1: 60 inc_0 inc_1 1.8511568 0.13746624 24.928167 1.326651
#> 2: 60 inc_1 inc_0 0.5402028 0.04011526 7.274513 1.326651
#> Risk Difference RD 95% LCI RD 95% UCI RD SE
#> <num> <num> <num> <num>
#> 1: 0.005616256 -0.02152428 0.03275679 0.01384746
#> 2: -0.005616256 -0.03275679 0.02152428 0.01384746